Updated: 4 November, 2025
26 May, 2025
You’ve probably heard the saying, “You can’t manage what you don’t measure.” If you are a CISO or head of an Application Security program, chances are you are using security metrics on a weekly basis. However, the question then becomes:
- Are you measuring the right things?
- Are you measuring them in the right way?
This is where our industry often goes off track. Instead of starting with clear goals and aligning the security metrics to them, we do the exact opposite. We pull whatever data our tools happen to offer, then scramble to invent goals that make those numbers look meaningful. Even worse, many of those tool-generated metrics are flawed by design.
In this blog, I’ll dig into two essential aspects of security metrics. First, we’ll explore their purpose. Why we measure in the first place, and what strategic impact we should be aiming for. Then, I’ll introduce the core qualities that make a security metric truly effective. If you’ve ever wondered whether your metrics are helping or just creating noise, this post is for you.
Watch a recording based on this article from our AppSec Science playlist.
![]() Watch on Youtube
Watch on Youtube
The problem with today’s security metrics
Let me start with a simple question: are the following good security metrics?
- Number of vulnerabilities
- Number of trainings completed
The answer is a probably no. There are at least two major issues here. First, what exactly are we trying to achieve with these numbers? If we go back to the old saying, “You can’t manage what you don’t measure,” we need to ask what we are managing, and what are our goals? More often than not, we skip that step. Our tools churn out these metrics by default, and instead of starting from our objectives, we try to retrofit some kind of purpose onto whatever data we already have. It’s a backwards approach, but it’s surprisingly common.
Suppose we reverse-engineer goals for the two metrics presented earlier.
|
Goal |
Metric |
|
Reduce the risk of being breached due to known vulnerabilities |
Number of vulnerabilities |
|
Security awareness |
Training completion |
<p>There are still two problems with this setup. Firstly, it’s not clear how those metrics actually help us answer the questions we care about. How high is really high? Does everyone need to take training even if people are highly aware? Secondly, both metrics have serious flaws. Take vulnerability counts. The vast majority (over 90%) are false positives or not exploitable in real-world scenarios. Completion doesn’t tell you anything about retention, behavior change, or impact. Maybe they already knew the material. Maybe they clicked through it while half-listening to a podcast.
Despite all this, security metrics like these are the de facto standard used to guide strategic decisions. They show up in board reports and in investment justifications. Yes, they are easy to collect, easy to visualize, but also easy to misunderstand. And that’s the core of the problem. We’re investing time, money, and trust into numbers that often rest on shaky foundation
s.
Metrics with purpose: Goal-Question-Metric framework
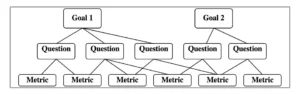
So let us start by introducing a framework that allows you to start with clear objectives, formulate questions to support the decision-making, and then design metrics to answer those questions.
Many organizations collect metrics because their tools provide them. These metrics are often treated as a starting point. Goals are then created to make the numbers seem useful. Instead of aligning metrics with strategy, many teams align strategy with whatever data is easiest to collect.
According to empirical studies, for measurement to be effective, it must be:
- Focused on specific goals.
- Interpreted based on characterization and understanding of the organizational context, environment and goals.
This means that metrics need to be defined in a top-down fashion. Without clear goals and models to guide interpretation, the meaning of raw data is ambiguous at best.
The Goal-Question-Metric (GQM) framework addresses this by reversing the common approach. Instead of starting with available data, GQM begins with strategic goals. From there, you formulate questions that help evaluate progress. Only then do you define metrics to answer those questions. This middle step, i.e., asking the right questions, is often skipped, which leads teams to draw conclusions directly from metrics.
Here’s how GQM works in a nutshell.
- Define your goal. What are you trying to achieve? It must be specific and tied to your organizational objectives.
- Formulate questions. What do you need to ask to understand whether you’re making progress?
- Identify metrics. What can you measure to answer those questions with evidence?
Let us revisit the context of the original metrics we had provided in the introduction section and create a meaningful GQM structure.
Goal-Question-Metric example: reduce the risk of being breached
The first example focuses on the context of vulnerabilities. The raw count of vulnerabilities tells us very little. Not all issues pose the same risk. Some are not exploitable. Others may exist only in test environments. Here are realistic goals, questions and reasonable metrics to start with.
- Goal: Reduce the risk of being breached due to known vulnerabilities
- Question 1: How many exploitable vulnerabilities exist in production
- Question 2: How many of those could realistically lead to a breach
- Metric 1: Number of confirmed vulnerabilities in production
- Metric 2: Likelihood score for each vulnerability
- Metric 3: Impact score for each vulnerability
The real goal is to reduce breach risk, not just reduce numbers on a dashboard. That’s why the supporting questions and metrics focus on likelihood and impact. Together, these give us a more accurate view of real risk. However, calculating impact often requires manual triage. This is time-consuming and costly. In practical, tool-driven settings, many organizations might consider skipping the impact metric. Still, even estimating likelihood can significantly improve decision-making over raw counts.
Goal-Question-Metric example: increase security awareness of developers
The second example is about developer awareness of secure coding practices. Developer security awareness can hardly be measured by training completion. A developer might click through slides while distracted. Others may already know the material, and for some, the training might not stick.
- Goal: Increase security awareness of the developers
- Question 1: What is the current level of security awareness?
- Question 2: Is developer awareness improving over time?
- Metric 1: Average scores on secure coding quizzes
- Metric 2: Number of security-related coding errors introduced during development
Quiz scores offer a better measure of knowledge retention. Tracking these over time gives you a sense of learning progress. But awareness alone isn’t enough. We care about behavior. The second metric shows whether developers are applying what they’ve learned.
Defining goals and questions is only the beginning. The real challenge comes next: designing metrics that produce accurate, consistent, and meaningful results. This is where measurement becomes a science of its own.
Good security metrics are precise, reliable and … hard to find
In this section, we explore the anatomy of a good metric. First, we examine how to measure the right things in the right way. Then, we look at how to ensure your metrics support sound conclusions based on the questions you formulated. Finally, we address a common but critical mistake in our industry: mixing incompatible data and applying flawed math that leads to misleading risk scores.
Metric precision, reliability, accuracy

Precision, reliability, and accuracy form the foundation of trustworthy metrics. While the definitions may seem simple, understanding their trade-offs is key to designing meaningful measurements.
Precision refers to the level of detail in a metric. The more precise the metric, the more information it could provide. For example, reporting quiz results on a 0 to 10 scale offers more insight than a simple pass or fail. Higher precision can be helpful, but it often requires more effort to collect and interpret. Not every situation demands extreme precision. It’s about choosing the right level for your context.
Reliability is about consistency. If you measure the same thing multiple times, you should get the same result. Think of a weighing scale. If it shows a slightly different number each time you step on it, that could signal a problem. Then again, a 0.1 percent variation might be acceptable. Reliability does not mean perfection. It means your measurements behave consistently within an acceptable margin.
Accuracy means your measurement reflects reality. If you know your weight is around 80 kg, but the scale says 95 kg, the metric is not accurate. Even if it is precise and reliable, it fails to measure what truly matters. Note that accuracy in the context of security metrics might often be unknown.
These three qualities often pull in different directions. Balancing all three is the real challenge. Let’s illustrate this with an example of secure coding quiz scores. Imagine we are testing the knowledge of five great developers with a similar level of awareness and knowledge.
| Metric | Description | Outcome | Precision | Reliability | Accuracy |
| M1 | Pass / Fail | Everyone passes | Low | High | High |
| M2 | Score from 0.0 to 10 | 2 developers have 4 on 10, 3 developers have 9 on 10 | Medium | Low (for two devs) | Mixed |
| M3 | Score from 0 to 1000 | Everyone scores 300 out of 1000 | Very High | High | Low |
While M1 offers the least precision, it clearly performs best in this example. It delivers reliable and accurate results, even if the detail is minimal.
Keep in mind that real-world decisions are rarely this simple. Imagine scaling to 100 developers. If M2 produces inaccurate scores for only 2 of them, it might still be acceptable, depending on the context. Also claiming that “five developers have a similar level of awareness and knowledge” might be highly subjective, i.e., inaccurate.
Metric validity and the metric-question gap
Even when your metrics are precise, reliable, and accurate, that does not guarantee they are useful. The real test is whether they help answer the questions you defined using the GQM approach. This is where metric validity comes into play. Validity determines whether a metric actually supports the decision-making it is meant to inform. Without it, even a well-constructed metric can lead you in the wrong direction. There are three main types of validity to watch out for.
Content validity
Metric content validity refers to how much of the target concept a metric actually covers. Take developer security awareness as an example.
- Metric 1: Training completion
- Metric 2: Percentage of top security risks addressed during the training
Metric 2 is clearly better. It captures the specific content we care about, i.e. familiarity with critical risks. Training completion alone tells us very little about what developers actually learned.
Criterion validity
Metric criterion validity is about how well the metric correlates with the intended outcome. Sticking with the same example, imagine three possible metrics:
- M1: Percentage of top security risks covered during training
- M2: Percentage of risks understood immediately after training
- M3: Percentage of risks remembered six months later
M1 and M2 are not bad, but M3 is more powerful. It tracks knowledge retention over time, which aligns more closely with real-world awareness.
Construct validity
Metric construct validity measures how well the metric aligns with the broader concept you are trying to capture. Suppose your question is: How well are we prepared for a real cyberattack?
- Metric 1: Scores from simulated attack exercises after training
- Metric 2: Performance during real-world security incidents
In this case, Metric 2 is stronger. It connects directly to actual events rather than artificial scenarios. While simulations are helpful, they do not always reflect the complexity or pressure of a real attack. Construct validity ensures your metric is grounded in reality, not just theoretical models.
Measurement scales and the math trap
Let’s assume your security metrics are reliable, precise, and accurate. They align well with your goals and questions. They even pass the test for validity. Still, there is one common mistake the industry continues to make without realizing it: treating all numbers as if they behave the same way. But not all numbers are created equal. To prove the point, here is a short quiz. Which of the following statements is true?
- Five XSS vulnerabilities are worse than one SQL injection
- One HIGH risk vulnerability is better than ten MEDIUM ones
- A vulnerability with a CVSS score of 5.0 is half as severe as one with a score of 10.0
- A vulnerability with an EPSS score of 0.5 is half as likely to be exploited as one with a score of 1.0
The only correct answer is the last one. Because EPSS scores use a ratio scale, which means the numbers have real meaning in terms of magnitude. A score of 1.0 is literally twice as likely as a score of 0.5. This is not true for the other examples.
Here is a brief overview of three of the four measurement scales and what operations they support.
| Scale Type | Example in Security Metrics | What It Measures | Allowed Operations |
| Nominal | Vulnerability types (e.g. XSS, SQLi, CSRF) | Categories without order | Count, mode |
| Ordinal | Severity levels (LOW, MEDIUM, HIGH), CVSS | Rank or order | Count, mode, median, comparisons (>, <) |
| Ratio | EPSS scores, time to remediate, exploit count | True zero, meaningful intervals | All mathematical operations (+, ×, ÷, etc.) |
Failing to respect measurement scales leads to invalid conclusions. Saying one HIGH is “worse than” ten MEDIUM vulnerabilities may sound intuitive, but mathematically, it has no foundation. These assumptions could end up distorting risk assessments and misguiding decision-making.
Data analysis: turning metrics into insights
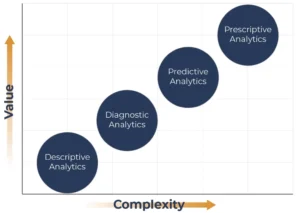
Imagine you have set your goals with GQM, you have rigorously selected metrics that are precise, reliable, accurate, valid and you are treating metric scales correctly. So what’s next? Do you just calculate averages, medians, modes?
Welcome to the world of data analysis, where security metrics become real insights. There are four major types of data analysis, each offering increasing levels of complexity and value.
- Descriptive analysis: What happened?
- Diagnostic analysis: Why did it happen?
- Predictive analysis: What is likely to happen next?
- Prescriptive analysis: What should we do about it?
We will not cover prescriptive analysis here, as it remains rare in real-world security operations and is often limited to academic or experimental settings. Instead, we will explore how to apply the first three techniques to get the most value out of your security metrics.
Descriptive analysis: what happened?
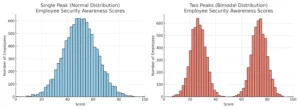
Descriptive analysis is the most basic and widely used data analysis method in security programs. Its purpose is simple: summarize and visualize data so you can understand what has already happened. In the context of security metrics, descriptive analysis helps you answer questions like:
- What is the average awareness score across the company?
- Who are the top and bottom performers?
You typically begin with straightforward statistics, like averages, medians, and frequency distributions. From there, you should use charts, graphs, and heatmaps to highlight trends or outliers. The type of visualization depends on the nature of the metric. Your judgment plays a key role in selecting the right view.
For example, imagine you are analyzing phishing test scores and consider you end up with the data as illustrated on the distribution charts above. The two data sets have exactly the same average, but are telling completely different stories. The right chart shows two clear peaks in performance. That pattern suggests your employees may fall into two distinct groups. The left one seems to have one group perhaps.
Diagnostic analysis: why did it happen?
While descriptive analysis shows what happened, diagnostic analysis helps you understand why it happened. It goes beyond surface-level summaries by comparing groups, identifying patterns, and uncovering relationships between variables. In security programs, diagnostic analysis often involves questions like:
- Do awareness scores vary significantly between business units?
- Are teams with more training sessions responding faster to incidents?
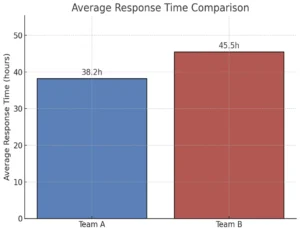
Let’s take a concrete example to illustrate the need for diagnostic analysis methods. Suppose Team A has an average response time of 38.2 hours, while Team B averages 45.5 hours. At first glance, it seems that Team A is faster. But can we confidently say that the difference is meaningful? To answer that, we need to leverage hypothesis testing. To prove something in diagnostic analysis we need to assume the opposite and disprove it. Here is how hypothesis testing works in a nutshell:
- Hypothesis (H): Team A is faster than Team B
- Null Hypothesis (H₀): There is no meaningful difference in response times
- Goal: Use statistical testing (such as a t-test) to determine if we can reject the null hypothesis
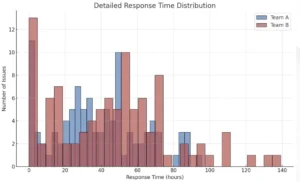
I will skip the details of the statistics, but in our case, the test yields a p-value of 0.076. That means we do not have strong enough evidence to reject the null hypothesis. In plain terms, the observed difference could be due to random variation rather than a real performance gap. If we look at the raw data we might actually spot that as there are clearly some outliers for Team B that took them quite some time to solve.
This is the essence of diagnostic analytics. It helps you avoid jumping to conclusions based on averages alone. Instead, you use statistical rigor to support or reject hypotheses and make decisions based on evidence rather than assumptions.
Predictive analysis: what will happen?
Predictive analytics focuses on forecasting future outcomes based on current and historical data. In security programs, predictive analysis helps you anticipate trends, identify at-risk groups, and plan targeted interventions before problems surface.
Predictive analysis starts by defining a dependent variable, i.e., the outcome you want to predict. Next, we choose relevant predictors. These are factors that may influence the outcome. With these inputs, you can then build a predictive model using statistical or machine learning techniques. In simple terms, the model is supposed to find patterns in the data to forecast future results.
Here is a simple, but highly realistic example you could try out. Consider that instead of a quiz we would like to use factors that correlate with developer secure coding awareness.
- Target outcome: Developer secure coding awareness score
- Predictors:
- Training engagement (completion rate, quiz scores)
- Tenure at the company
- Developer role (e.g. frontend, backend, DevOps)
- Number of code reviews with security feedback
The predictors are based on our intuitive understanding of secure coding awareness. Namely that a developer who actively engages in training, has been with the company for a while, and receives regular security-related feedback in code reviews is more likely to have strong awareness. But then again, keep in mind that the reality might not be that simple and we would need to test the predictor rigorously before using it in real life.
Recap through a realistic example
Let’s bring everything together with a practical example. Suppose your organization has a strategic goal to increase the security awareness of all employees. This is a common objective in most security programs, but measuring progress requires the right metrics and analysis techniques.
We start with the GQM framework:
- Goal: Improve security awareness across the organization
- Question 1: What is the current level of awareness?
- Question 2: How is awareness evolving over time?
Based on these questions, we choose two metrics that reflect both current status and future trends.
Metric 1: Security knowledge assessment score (quiz)
This metric captures how well employees understand key security topics, such as phishing, password hygiene, and data handling.
- Descriptive analysis: Calculate the average score and track changes over time to monitor overall progress.
- Diagnostic analysis: Compare scores across teams, departments, or regions to identify areas that may need extra attention.
This allows you to answer the “what” and the “why” behind awareness levels using reliable, structured data.
Metric 2: Security knowledge predictor
To move from insight to foresight, you can build a predictive model that estimates future awareness scores based on key indicators like training participation, tenure, job role, or prior incident involvement.
- Predictive analysis: Use statistical or machine learning techniques to forecast which employees or teams might need additional support before awareness drops.
This approach helps security teams act early, allocate training resources more efficiently, and tailor interventions to where they are most needed.
Conclusion
Security metrics are to your cybersecurity program what blood tests are to a patient’s health. Yet, while medicine relies on proven diagnostic science, much of the security industry is still guessing. We are glancing at whatever numbers our tools produce and trying to make sense of them after the fact. It’s like ignoring lab results and judging a patient’s condition by the smell of their blood.
We can do better. In fact, we already know how. To make metrics meaningful, we must take a top-down approach. Start with clear goals. Ask the right questions. Choose metrics that are reliable, precise, and accurate. Use the correct measurement scales. And finally, apply the right data analysis techniques to draw useful conclusions.
Security metrics are not just charts for reports. They are decision tools. When designed and used properly, they guide strategic choices, reveal hidden risks, and help your team act with clarity and confidence. The science is there. The choice to apply it is yours.
References
- Software Modeling and Measurement: The Goal/Question/Metric Paradigm
- Guide to Advanced Empirical Software Engineering
- How to Measure Anything in Cybersecurity Risk
- Security Metrics: A Beginner’s Guide